


Dieci giorni fa scrivevo che GPT-5 non è un upgrade, è un nuovo partner cognitivo. Una definizione che resta valida, supportata da dati concreti: finestra di contesto più ampia del 30%, allucinazioni ridotte di 5-6 volte, performance di coding che toccano il 74.9% su SWE-bench Verified [1]. Il modello GPT5 Thinking dimostra capacità di ragionamento che vanno oltre il semplice "autocomplete sofisticato" di cui parlava Sam Altman.
Eppure, c'è qualcosa che non torna.
Mentre i benchmark celebrano numeri da record, una sensazione diversa serpeggia tra gli utenti. Cognizione fredda. Distacco. Una brillantezza tecnica che sembra aver perso quella scintilla umana che rendeva GPT-4o così coinvolgente. "Troppo freddo, troppo generico, come GPT-4 mini ma con una memoria migliore", scrive un utente su Reddit [2]. Non è solo una percezione isolata: Medium titola "GPT-5: il peggior rilascio di OpenAI di sempre", The Verge parla di un modello che "ha fallito il test dell'hype" [3].
Come può un sistema tecnicamente superiore risultare così deludente? La risposta potrebbe risiedere in una verità scomoda che l'industria dell'AI sta iniziando a confrontare: l'illusione della scala infinita. L'idea che più parametri, più compute, più dati equivalgano automaticamente a più intelligenza. Un paradigma che GPT-5, nel suo paradosso di eccellenza tecnica e freddezza percepita, potrebbe aver definitivamente infranto.
Sam Altman e la bolla dell’AI

ChatGPT oggi arriva a oltre 700 milioni di persone ogni settimana. Eppure lo stesso CEO di OpenAI, Sam Altman, avverte: potremmo essere dentro una bolla dell’intelligenza artificiale [29].
Alle bolle non manca mai un fondo di verità. Altman lo ricorda: Internet era reale, fondamentale. Anche le dot-com avevano un nucleo autentico, così come le criptovalute e persino il mattone dei primi anni 2000. Eppure l’entusiasmo degli investitori porta sempre a un eccesso: il prezzo corre più veloce del valore reale.
L’intelligenza artificiale oggi è senza dubbio la tecnologia più importante degli ultimi decenni, e il suo impatto sarà di lungo periodo. Ma la corsa spasmodica di capitali e startup ci dice che siamo in quella fase del ciclo in cui la realtà e la speculazione si intrecciano.
La verità è che in America le bolle non sono anomalie: sono strutturali. Sono il cuore pulsante del loro ciclo dell’hype, il meccanismo con cui l’economia tecnologica si rigenera, esplode e rinasce.
Promessa e Realtà: Il Paradosso delle Performance
I numeri di GPT-5 raccontano una storia di successo inequivocabile. Sul fronte del coding, il modello raggiunge l'88% su Aider Polyglot, il 74.9% su SWE-bench Verified, superando nettamente il 69.1% di o3 e il 30.8% di GPT-4o [4]. Nel settore healthcare, GPT-5-thinking ottiene il 25.5% su HealthBench Hard, mentre su GPQA, un benchmark di domande a livello esperto, GPT-5 Pro raggiunge l'88.4% [5]. Su AIME 2025 math, quando utilizza Python per rispondere, tocca il 100%.
Questi non sono miglioramenti incrementali. Sono salti quantici.
Il controllo delle allucinazioni rappresenta forse il breakthrough più significativo. Invece di rifiutare categoricamente domande potenzialmente problematiche, GPT-5 utilizza "completamenti sicuri" - risposte ad alto livello che forniscono informazioni utili rimanendo entro vincoli di sicurezza [6]. È un approccio più sofisticato che riconosce la complessità del mondo reale, dove le risposte binarie sono spesso inadeguate.
Ma c'è un'altra storia che i benchmark non raccontano.
"Il feedback degli utenti è orribile. Il modello viene massacrato da tutte le parti", scrive Mehul Gupta su Medium, in un articolo che non usa mezzi termini: "GPT-5: il peggior rilascio di OpenAI di sempre" [7]. Su Reddit, gli utenti descrivono un'esperienza frustrante: "Chat GPT 5 non è mai stato creato per essere un modello nuovo e più potente... è freddo, troppo generico" [8]. The Verge è altrettanto diretto: "GPT-5 ha fallito il test dell'hype" [9].

Il paradosso è stridente. Come può un modello tecnicamente superiore risultare così insoddisfacente nell'uso quotidiano? La risposta potrebbe risiedere in una differenza fondamentale tra competenza tecnica e intelligenza percepita. GPT-5 eccelle nei task misurabili, ma sembra aver perso quella qualità ineffabile che rendeva GPT-4o così coinvolgente: la capacità di sorprendere, di essere imprevedibilmente brillante, di mostrare quella scintilla di creatività che gli utenti interpretavano come "intelligenza".
C’è poi l’aggiustamento della Sycophancy da parte di OpenAI che pur essendo una misura a favore degli utenti ha finito con l’essere un boomerang, forse proprio perché in un’epoca di relazioni umane scadenti un’AI che ti coccola emotivamente è qualcosa di cui le persone, purtroppo, hanno bisogno. Quando OpenAI ha tolto l’accesso ai modelli legacy si è registrato il panico di molti utenti, alcuni nutrono una sorta di relazione intima con l’AI (un remake di questa scena di Her del 2013).
Aaron Levie, CEO di Box, aveva testato GPT-5 su dataset complessi definendolo "una svolta completa" [10]. Ma i test aziendali su dataset strutturati sono una cosa. L'interazione quotidiana con milioni di utenti è un'altra. E qui emerge una verità scomoda: l'ottimizzazione per i benchmark potrebbe aver sacrificato l'esperienza umana.

C'è un'altra interpretazione, più cinica ma forse più accurata. Come suggerisce un commento su Hacker News: "GPT5 è davvero una misura di riduzione dei costi, con un'azienda che sta cercando di crescere fino a un miliardo di utenti su un prodotto che ha bisogno di GPU" [11]. Se questa teoria è corretta, GPT-5 non è il culmine dell'innovazione AI, ma il primo segnale che anche OpenAI sta confrontandosi con i limiti economici dello scaling infinito.
La Strategia del Modello Giusto: Quando Non Usare GPT-5

Non usare GPT-5 per ogni progetto o te ne pentirai. Questa affermazione, che potrebbe sembrare controintuitiva, rivela una verità fondamentale: l'efficienza produttiva non dipende dalla tecnologia più recente, ma dalla capacità di abbinare il tool specifico all'obiettivo da raggiungere.
I modelli legacy di ChatGPT superano spesso GPT-5 in compiti specifici. Questo crea un'opportunità strategica per chi sa scegliere lo strumento giusto al momento giusto. È la competenza che distingue i professionisti dall'hype.
L'Ecosistema dei Modelli Specializzati
GPT-4.1 trasforma documenti complessi in applicazioni web interattive, gestendo simultaneamente analisi testuale e sviluppo di codice con una fluidità che GPT-5, nella sua ottimizzazione per i costi, fatica a replicare. Il 4o interpreta contenuti scritti a mano e li converte in dashboard funzionali con filtri navigabili - una capacità che rimane superiore nonostante l'arrivo del modello più recente.
Il 4o-mini eccelle nell'analisi visiva di grafici aziendali, generando insight automatici sui trend di business con una precisione che spesso supera GPT-5 in scenari specifici. L'o3 si dimostra particolarmente utile a gestire scenari che includono testo, immagini e codice in modo integrato.
La Finestra di Contesto Come Fattore Decisivo
Ogni modello ha una finestra di contesto diversa che determina quante informazioni può processare in una sessione. Questa caratteristica influenza direttamente la qualità dell'output per progetti articolati. Non sempre la finestra più ampia è quella ottimale - a volte la precisione di un modello più focalizzato supera la capacità bruta di elaborazione.
La Competenza Strategica
Chi allena questa competenza ottiene risultati superiori e coerenti con meno sforzo. Mentre l'industria si concentra sulla corsa al modello più grande, i professionisti intelligenti costruiscono un arsenale di strumenti specializzati. È la differenza tra chi usa un martello per ogni problema e chi ha una cassetta degli attrezzi completa.
Questa strategia non è solo più efficace - è anche più economica. Utilizzare GPT-4o-mini per analisi visive semplici invece di GPT-5 può ridurre i costi del 90% mantenendo la stessa qualità. È l'antitesi dell'illusione della scala infinita: più intelligenza attraverso la selezione, non la forza bruta.
Il Sospetto del Plateau: Quando i Profeti Hanno Ragione

Bill Gates non è mai stato uno che si lascia trascinare dall'hype. Oltre due anni fa, quando l'euforia per ChatGPT era al suo apice, l'ex CEO di Microsoft aveva fatto una previsione che suonava quasi eretica: la tecnologia di OpenAI aveva raggiunto un plateau. GPT-5, sosteneva, non avrebbe offerto miglioramenti significativi rispetto ai modelli precedenti [12].
La storia gli sta dando ragione in modi che forse nemmeno lui immaginava.
Gates non aveva mai sostenuto che lo sviluppo dell'AI fosse finito. Come precisa un'analisi su Medium, aveva specificamente notato che "con nuove ricerche, l'AI potrebbe scalare nuove vette, rendendola più affidabile" [13]. Il punto non era la fine dell'innovazione, ma la fine di un paradigma: quello dello scaling bruto come via maestra verso l'intelligenza artificiale generale.
Le Evidenze del Plateau Sono Ovunque
I dati parlano chiaro. TechCrunch, a novembre 2024, titolava senza ambiguità: "Le attuali leggi di scaling dell'AI mostrano ritorni decrescenti, costringendo i laboratori AI a cambiare rotta" [14]. The New Yorker, ancora più diretto: "Se costruire modelli sempre più grandi stava producendo ritorni decrescenti, le aziende tecnologiche avrebbero avuto bisogno di una nuova strategia" [15].

Un nuovo studio rivela che l'era del "più grande è meglio" nell'AI si sta probabilmente avvicinando ai suoi limiti [16]. GovInfoSecurity documenta come "scalare i modelli AI di ragionamento si sta rivelando più difficile che scalare la percezione" [17].
Ma è quando si guardano i numeri che la situazione diventa davvero preoccupante.
I Costi Esplosivi: La Matematica del Plateau
Uno studio di Stanford del 2023 rivela che la potenza computazionale necessaria per addestrare modelli AI raddoppia ogni 3.4 mesi dal 2012 [18]. Il training compute per i modelli frontier raddoppia ogni cinque mesi [19]. Questa crescita esponenziale dei costi non è sostenibile indefinitamente, nemmeno per giganti come Microsoft, Google o Amazon.
The New Yorker documenta che le aziende tech hanno speso 560 miliardi di dollari in spese di capitale legate all'AI negli ultimi diciotto mesi [20]. Una cifra astronomica che evidenzia come l'industria stia bruciando risorse a un ritmo insostenibile.
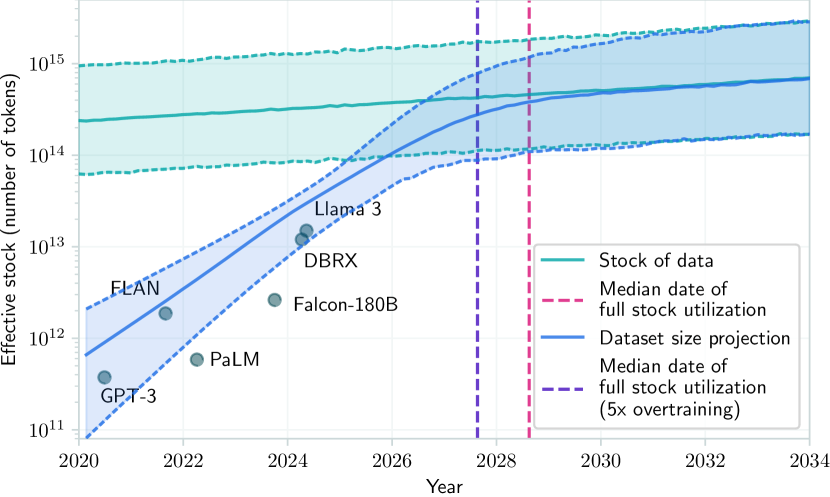
Il problema non è solo economico. È fisico. La scarsità di dati di alta qualità sta diventando un collo di bottiglia critico. Come nota Pareto.AI, "La scarsità di dati è il più grande ostacolo al futuro dell'AI?" [21]. Abbiamo già consumato gran parte del testo disponibile su internet. I dati sintetici possono aiutare, ma introducono bias e limitazioni proprie.
Il Caso Orion: La Prova del Plateau
La prova più concreta del plateau arriva dal progetto interno di OpenAI chiamato "Orion". Secondo The Decoder, "Orion si è bloccato prima di poter guadagnare il nome GPT-5. Fino a giugno 2025, nessuno dei modelli in sviluppo presso OpenAI era considerato abbastanza forte da essere chiamato GPT-5" [22].
 Originally developed as Orion and planned as GPT-5. Performance disappointing: no major leaps forward compared to GPT-4o. Reasons for")
Reddit riporta che "Orion doveva offrire un grande passo avanti nelle performance rispetto all'attuale flagship, GPT-4o, rilasciato a maggio" [23]. Ma i risultati sono stati deludenti, costringendo OpenAI a ripensare la sua strategia.
La Scienza Conferma: Ritorni Decrescenti Inevitabili
Un paper del 2025 su Neural Computation fornisce una spiegazione teorica del perché i ritorni decrescenti sono inevitabili: "Perché set di addestramento più grandi devono produrre ritorni decrescenti: Un limite di velocità teorico-informativo per l'AI" [24]. La ricerca dimostra matematicamente che ogni elemento di addestramento aggiuntivo non può fornire la stessa quantità di informazioni del precedente.

IEEE Spectrum, già nel 2021, aveva previsto questa situazione: "I ritorni decrescenti del deep learning: Il costo del miglioramento sta diventando insostenibile" [25]. Lo studio, con 215 citazioni, aveva analizzato oltre 1.000 paper di ricerca sul deep learning, documentando come i costi stessero crescendo più velocemente dei benefici.
Un paper accademico del 2025, "Limiti alla Crescita dell'AI: Le Conseguenze Ecologiche e Sociali dello Scaling", è brutalmente chiaro: "Ritorni decrescenti... limitano la capacità di scalare i modelli" [26]. Con 85 citazioni, "I costi crescenti dell'addestramento di modelli AI di frontiera" documenta come i costi stiano crescendo più velocemente dei benefici [27].
Gartner Conferma: L'AI Generativa Scivola nel "Trogolo della Disillusione"
Il Gartner Hype Cycle 2025 mostra l'AI Generativa che scivola nel "Trogolo della Disillusione" [28]. Questo non è un caso isolato, ma il riflesso di un'industria che sta realizzando i limiti del paradigma attuale.
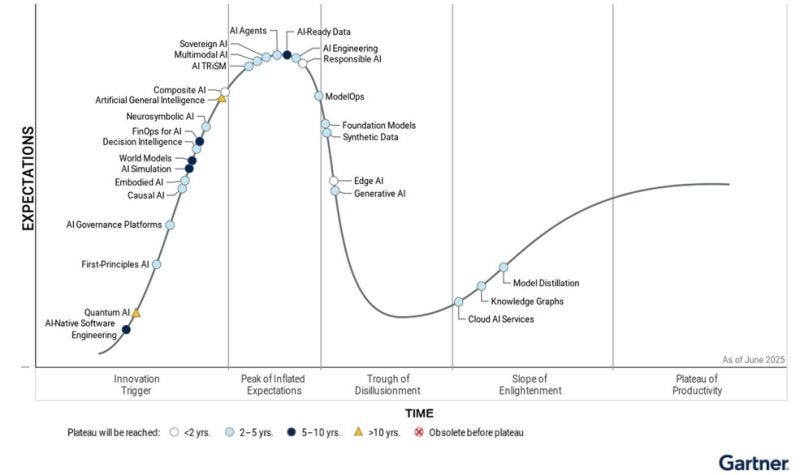
Il plateau non è una teoria. È una realtà matematica, economica e fisica.
E GPT-5, con la sua eccellenza tecnica ma freddezza percepita, potrebbe essere il primo modello a incarnare questo nuovo paradigma: massima efficienza nei benchmark, minima sorpresa nell'esperienza umana. Un'intelligenza artificiale ottimizzata per i costi, non per la meraviglia.
La Fallacia della Forza Bruta: La Scala Verso la Luna
Immaginate di voler raggiungere la luna costruendo una scala. Ogni gradino richiede più materiale del precedente, più ingegneri, più tempo. All'inizio i progressi sono evidenti: dal primo piano si sale al secondo, poi al terzo. Ma a un certo punto, guardando verso l'alto, ci si rende conto che la luna è ancora infinitamente lontana, mentre le risorse sono finite.

Questa è la metafora perfetta per comprendere l'illusione dello scaling infinito nell'AI.
Per decenni, l'industria dei semiconduttori ha vissuto secondo la Legge di Moore: ogni due anni, il numero di transistor su un chip raddoppiava. Era una crescita esponenziale che sembrava inarrestabile. Fino a quando non si è scontrata con i limiti fisici degli atomi. L'AI sta vivendo lo stesso momento di verità.
La Traiettoria Insostenibile dei Parametri
I modelli linguistici di grandi dimensioni hanno seguito una traiettoria simile. Più parametri significavano migliori performance. GPT-1 aveva 117 milioni di parametri. GPT-2 ne aveva 1.5 miliardi. GPT-3 è saltato a 175 miliardi. GPT-4 si stima abbia superato i 1000 miliardi. Ogni salto portava capacità nuove, sorprendenti.
Ma GPT-5 racconta una storia diversa.
Nonostante le performance tecniche impressionanti, il salto qualitativo percepito dagli utenti è minimo. Anzi, molti lo descrivono come un passo indietro in termini di esperienza. È il primo segnale che la curva dei ritorni si sta appiattendo. Che stiamo raggiungendo i limiti di ciò che lo scaling puro può ottenere.
Il Problema Fondamentale: Simulazione vs Comprensione
Il problema fondamentale è che i modelli attuali non comprendono davvero. Sono simulatori incredibilmente sofisticati, capaci di produrre testo che sembra intelligente, ma privi di vera comprensione del mondo. Come ho sentito una volta dire a un ricercatore: "È come avere un pappagallo infinitamente eloquente che può ripetere qualsiasi cosa abbia mai sentito, ma non sa cosa significhi volare".
Questa limitazione diventa evidente quando si esce dai domini ben definiti dei benchmark. GPT-5 eccelle su SWE-bench perché il coding ha pattern riconoscibili, regole chiare. Ma nell'interazione umana quotidiana, dove conta l'intuizione, l'empatia, la capacità di sorprendere, mostra i suoi limiti.
La Matematica dei Ritorni Decrescenti
La forza bruta ha raggiunto il suo plateau. Come documenta un'analisi su arXiv, "Le tendenze empiriche suggeriscono che i guadagni di efficienza sostenuti possono spingere lo scaling dell'AI ben oltre il prossimo decennio, fornendo una nuova prospettiva sui ritorni decrescenti" [30]. Ma "guadagni di efficienza sostenuti" è un eufemismo per dire che i miglioramenti futuri saranno incrementali, non rivoluzionari.
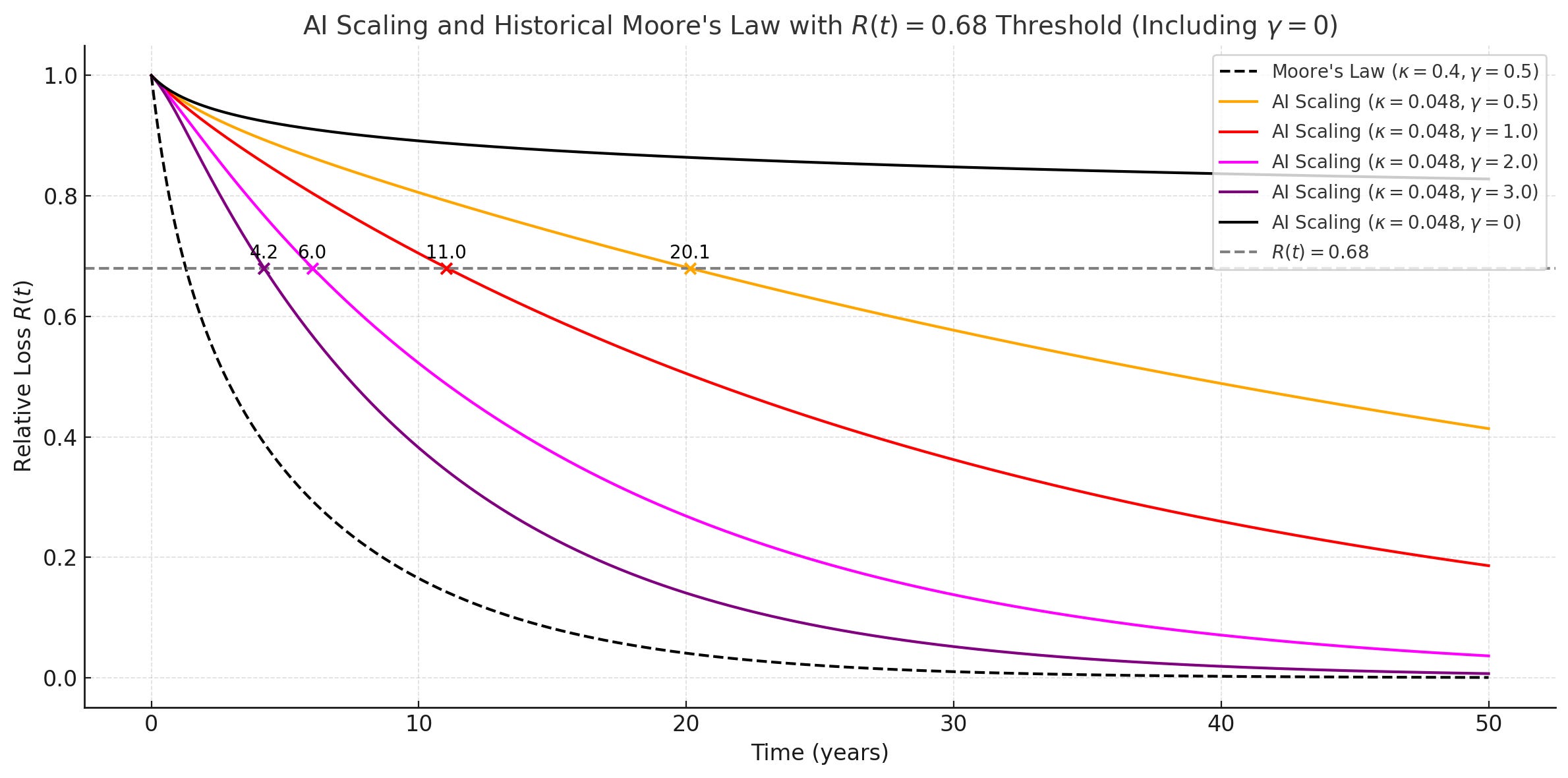
Un nuovo studio su ScienceDirect conferma che "il boom dell'AI potrebbe essere un fenomeno temporaneo, guidato da abbondanti opportunità di apprendimento precoce e disponibilità di dati. I ritorni decrescenti all'apprendimento dell'AI implicano che..." [31] la crescita esponenziale non può continuare indefinitamente.
Il Costo della Realizzazione
Il costo di questa realizzazione è già visibile. OpenAI, secondo alcune interpretazioni, ha progettato GPT-5 non per stupire, ma per ottimizzare i costi operativi mentre scala verso un miliardo di utenti. È una strategia razionale dal punto di vista aziendale, ma segna la fine dell'era dell'innovazione guidata dalla pura ambizione tecnologica.
La scala verso la luna si è rivelata per quello che è: un'illusione. La luna richiede un razzo, non una scala più alta.
Le Strade Alternative dell’AI
Se la scala verso la luna è un'illusione, quali sono i razzi che potrebbero davvero portarci lì?

La risposta potrebbe trovarsi in un organo che pesa appena 1.4 chilogrammi ma consuma solo 20 watt: il cervello umano. Mentre GPT-5 richiede data center che consumano megawatt per operare, il cervello umano elabora informazioni, ragiona, crea e sogna con l'energia di una lampadina. Non è solo una questione di efficienza energetica. È una questione di architettura fondamentalmente diversa.
L'Efficienza Biologica Come Modello
Il neuromorphic computing rappresenta il primo tentativo serio di replicare questa efficienza. Invece di elaborare informazioni in modo sequenziale come i processori tradizionali, i chip neuromorphici imitano la struttura parallela e event-driven del cervello [32].

Brainchip, con il suo processore Akida, ha dimostrato che è possibile integrare AI e machine learning su un singolo system-on-chip utilizzando spiking neural networks (SNNs) [33]. Questi sistemi non elaborano dati continuamente, ma solo quando ricevono "spike" - eventi discreti che mimano i potenziali d'azione dei neuroni biologici.
Nature, in un paper del 2025, è chiaro sulle potenzialità: "La tecnologia neuromorfica a ultra-basso consumo troverà casa in sistemi alimentati a batteria, calcolo locale per dispositivi internet-of-things e wearable per consumatori" [34]. Non stiamo parlando di sostituire i data center, ma di ridistribuire l'intelligenza dove serve davvero.
Embodied AI: L'Intelligenza che Tocca il Mondo
Un'altra strada promettente è l'embodied AI - intelligenza artificiale che interagisce fisicamente con il mondo reale. Mentre i modelli linguistici vivono in un universo di testo, l'embodied AI impara attraverso l'esperienza sensoriale diretta [35].

NVIDIA definisce l'embodied AI come "l'integrazione dell'intelligenza artificiale in sistemi fisici, permettendo loro di interagire con il mondo fisico" [36]. Ma è più di una definizione tecnica. È un cambio di paradigma che riconosce che l'intelligenza vera emerge dall'interazione con l'ambiente, non dall'elaborazione di testo.
AI2 ha dimostrato che "rimuovendo la necessità di costosa raccolta di dati del mondo reale, il nostro approccio rende molto più facile scalare l'embodied AI" [37]. Il paradosso è affascinante: per scalare l'AI embodied, bisogna smettere di scalare i modelli tradizionali.
Architetture Ibride: Il Meglio di Due Mondi
Forse la strada più promettente è quella degli ibridi simbolico-statistici. Sistemi che combinano la capacità di pattern recognition delle reti neurali con la logica esplicita dell'AI simbolica [38].
Le XNNs (eXplainable Neural Networks) rappresentano un esempio concreto: "architetture neurali trasparenti strutturate per facilitare l'interazione con sistemi simbolici" [39]. Non sono solo reti neurali più grandi, ma architetture fondamentalmente diverse che possono ragionare esplicitamente sui loro processi interni.
SmythOS descrive bene il potenziale: "L'AI simbolica, con il suo ragionamento simile a quello umano attraverso regole esplicite e logica, e le reti neurali, che eccellono nell'apprendere pattern da vaste quantità di dati" [40]. L'idea è semplice ma rivoluzionaria: invece di fare tutto con una sola architettura, usare l'architettura giusta per ogni compito.
La Rivoluzione Silenziosa
Queste tecnologie non fanno rumore come i lanci di GPT-5. Non generano titoli sui giornali o valutazioni miliardarie. Ma stanno silenziosamente ridefinendo cosa significa "intelligenza artificiale".
Il neuromorphic computing sta già trovando applicazioni in "calcolo scientifico, intelligenza artificiale, realtà aumentata e virtuale, wearable, agricoltura intelligente" [41]. L'embodied AI sta rivoluzionando la robotica industriale. Gli ibridi simbolico-statistici stanno risolvendo problemi che i modelli puramente neurali non riescono nemmeno ad affrontare.
Il futuro dell'AI non sarà scritto nei petaflop, ma nell'eleganza dell'architettura.
Mentre OpenAI ottimizza GPT-5 per servire un miliardo di utenti con il minor costo possibile, una rivoluzione silenziosa sta accadendo nei laboratori di ricerca. Una rivoluzione che non punta verso modelli sempre più grandi, ma verso sistemi sempre più intelligenti.
Il Limite Strutturale: Oltre il Linguaggio Stesso
Ma forse il problema più profondo non risiede nella scala o nell'architettura. Forse risiede nel substrato stesso su cui abbiamo costruito l'intelligenza artificiale: il linguaggio naturale.
Ogni azienda che implementa l'intelligenza artificiale incontra le stesse barriere: allucinazioni, output incoerenti e ragionamenti inaffidabili. Il percorso convenzionale - il ridimensionamento dei modelli, l'accumulo di più dati, il perfezionamento della messa a punto - ha prodotto progressi, ma elude un problema fondamentale: abbiamo progettato le macchine per ragionare attraverso l'ambiguità del linguaggio naturale.
L'Ambiguità Intrinseca del Linguaggio
Considera i difetti intrinseci del linguaggio come substrato cognitivo:
"Banca" evoca fiumi o finanze. Il "lead" si sposta tra gli elementi e la guida. "Set" comprende oltre 400 definizioni. Ancorando la cognizione dell'IA in un mezzo così fluido, invitiamo gli errori. Le allucinazioni non sono anomalie - sono sintomi di un substrato non corrispondente.
Come avvertiva Wittgenstein, "i limiti del mio linguaggio significano i limiti del mio mondo".
Forse ora abbiamo raggiunto quel limite con l'intelligenza artificiale. E i post-modernisti sono andati oltre: il linguaggio stesso è instabile, i significati scivolano e si spostano all'infinito. Se questo è vero, allora le allucinazioni negli LLM non sono fallimenti dell'ingegneria - sono l'inevitabile conseguenza del ragionamento a parole.
Il Post-Linguistic Reasoning Substrate (PLRS)

Stephen Klein, Founder & CEO di Curiouser.AI, propone il Post-Linguistic Reasoning Substrate (PLRS): un quadro cognitivo interno in cui l'IA conduce il ragionamento in un codice preciso, verificabile e componibile, simile alla matematica o alla logica formale [42].
Il linguaggio naturale rimane l'interfaccia utente, ma l'elaborazione di base traduce gli input in PLRS, esegue operazioni formali e riconverte gli output. È come se l'AI pensasse in "matematica pura" e poi traducesse i risultati in linguaggio umano.
I Vantaggi del PLRS
Questo cambiamento promette trasformazioni radicali:
Drastica riduzione degli errori: la precisione sostituisce l'interpretazione poetica. Quando l'AI ragiona in logica formale, l'ambiguità scompare. Non ci sono più interpretazioni multiple di "banca" - solo definizioni precise e contestualizzate.
Verificabilità per le imprese: i risultati diventano tracciabili, favorendo la fiducia nelle applicazioni ad alto rischio. Ogni passaggio logico può essere ispezionato, validato, corretto. È la differenza tra fidarsi di una "sensazione" e seguire una dimostrazione matematica.
Efficienza rispetto alla scala: focus sull'innovazione del substrato, non sulla crescita infinita dei parametri. Invece di modelli sempre più grandi che elaborano linguaggio ambiguo, modelli più intelligenti che ragionano in logica pura.
L'Analogia Storica
Storicamente, ci siamo evoluti dal codice macchina a linguaggi di alto livello come Python per migliorare l'interazione uomo-computer. PLRS inverte questo: potenziare le macchine liberandole dalla confusione linguistica.
È come se avessimo scoperto che far ragionare i computer in linguaggio naturale è come farli calcolare in numeri romani invece che in binario. Funziona, ma è inefficiente e soggetto a errori.
Il Python della Cognizione
Le implicazioni sono profonde. Padroneggiare il "Python della cognizione" potrebbe rimodellare l'infrastruttura dell'IA per il prossimo decennio. Non stiamo parlando di un miglioramento incrementale, ma di un cambio di paradigma fondamentale.
Questo non è solo tecnico - è un riconoscimento filosofico che il linguaggio, sebbene espressivo, manca del rigore per un pensiero automatico impeccabile. È l'ammissione che abbiamo costruito i nostri sistemi più avanzati su fondamenta intrinsecamente instabili.
La Domanda Fondamentale
La domanda non è come scalare ulteriormente, ma se abbiamo costruito sulle giuste basi. GPT-5, con la sua freddezza percepita nonostante l'eccellenza tecnica, potrebbe essere il primo segnale che abbiamo raggiunto i limiti di ciò che il linguaggio naturale può offrire come substrato cognitivo.
Il futuro dell'AI potrebbe non essere scritto in token linguistici, ma in simboli logici puri. E chi per primo padroneggerà questo "linguaggio del pensiero artificiale" avrà un vantaggio competitivo decisivo.
Il Futuro non è scritto nello scaling infinito
GPT-5 resta un partner cognitivo valido. I suoi benchmark parlano chiaro: 74.9% su SWE-bench, controllo delle allucinazioni migliorato, capacità di reasoning che vanno oltre i modelli precedenti. È tecnicamente superiore a tutto ciò che l'abbiamo preceduto.
Ma GPT-5 è anche qualcos'altro: il primo modello a mostrarci chiaramente i limiti del paradigma dello scaling a forza bruta. La sua freddezza percepita, il feedback negativo degli utenti, la sensazione diffusa che qualcosa sia andato perduto nel passaggio da GPT-4o, non sono bug. Sono feature di un nuovo paradigma dove l'ottimizzazione per i costi e l'efficienza operativa prevalgono sulla meraviglia dell'innovazione.
La Strategia della Selezione Intelligente
La lezione pratica è immediata: non usare GPT-5 per ogni progetto. Chi padroneggia l'arte di scegliere il modello giusto per il compito giusto ottiene risultati superiori con meno sforzo. È l'antitesi dell'illusione della scala infinita: più intelligenza attraverso la selezione strategica, non la forza bruta.
GPT-4.1 per applicazioni web complesse, 4o per analisi visive, 4o-mini per task specifici, o3 per scenari multimodali. Ogni modello ha la sua finestra di eccellenza. Chi costruisce un arsenale di strumenti specializzati supera chi insegue sempre l'ultimo modello.
Il Plateau Come Realtà Matematica
Bill Gates aveva visto giusto. Non perché l'AI avesse smesso di progredire, ma perché il progresso aveva cambiato natura. I 560 miliardi di dollari spesi dalle tech companies negli ultimi 18 mesi, il caso Orion che si è "bloccato" prima di diventare GPT-5, il Gartner Hype Cycle che mostra l'AI Generativa scivolare nel "Trogolo della Disillusione" - tutto conferma che il plateau non è una teoria, ma una realtà matematica.
Oltre il Linguaggio Stesso
Ma forse la rivelazione più profonda riguarda il substrato stesso dell'intelligenza artificiale. Le allucinazioni non sono bug da correggere - sono sintomi inevitabili del ragionare attraverso l'ambiguità del linguaggio naturale. Il Post-Linguistic Reasoning Substrate rappresenta un cambio di paradigma: far pensare l'AI in logica pura e tradurre solo l'output in linguaggio umano.
Le Strade del Futuro
Il neuromorphic computing ci insegna che l'intelligenza non è una questione di dimensioni, ma di architettura. Un cervello umano con i suoi 86 miliardi di neuroni e 20 watt di consumo è più intelligente di qualsiasi data center. L'embodied AI ci ricorda che l'intelligenza emerge dall'interazione con il mondo reale. Gli ibridi simbolico-statistici dimostrano che combinare approcci diversi può essere più potente che scalare un singolo approccio all'infinito.
La Vera Lezione di GPT-5
La vera lezione di GPT-5 non è nei suoi successi, ma nei suoi limiti. Ci mostra che siamo arrivati alla fine di un'era - l'era dello scaling infinito - e all'inizio di un'altra: l'era dell'intelligenza architettata.
Il futuro dell'AI non sarà scritto nei petaflop dei data center, ma nell'eleganza delle architetture che sapranno combinare efficienza biologica, interazione fisica, ragionamento ibrido e substrati post-linguistici. Non avremo bisogno di scale più alte per raggiungere la luna. Avremo bisogno di razzi più intelligenti.
GPT-5, con tutti i suoi paradossi, potrebbe essere ricordato non come il culmine dell'AI, ma come il momento in cui l'industria ha finalmente capito che più grande non significa necessariamente più intelligente. E che l'intelligenza artificiale generale, quando arriverà, avrà un aspetto molto diverso da quello che immaginavamo.
L'illusione della scala infinita è finita. È tempo di costruire razzi.
Referenze
[1] OpenAI. "Introducing GPT-5 for developers." https://openai.com/index/introducing-gpt-5-for-developers/ (7 agosto 2025)
[2] Reddit. "Chat GPT 5 was not for use, it was to get rid of free users all along." https://www.reddit.com/r/ChatGPT/comments/1mlkemm/chat_gpt_5_was_not_for_use_it_was_to_get_rid_of/ (9 agosto 2025)
[3] The Verge. "GPT-5 failed the hype test." https://www.theverge.com/openai/759755/gpt-5-failed-the-hype-test-sam-altman-openai (2 giorni fa)
[4] Passionfruit. "GPT-5 vs o3 vs 4o vs GPT-5 Pro — 2025 Benchmarks & Best Uses." https://www.getpassionfruit.com/blog/chatgpt-5-vs-gpt-5-pro-vs-gpt-4o-vs-o3-performance-benchmark-comparison-recommendation-of-openai-s-2025-models (7 agosto 2025)
[5] Vellum AI. "GPT-5 Benchmarks." https://www.vellum.ai/blog/gpt-5-benchmarks (7 agosto 2025)
[6] Yuan, Y., et al. "From Hard Refusals to Safe-Completions: Toward Output-Centric Safety Training." arXiv preprint arXiv:2508.09224 (2025)
[7] Gupta, Mehul. "GPT-5: OpenAI's Worst Release Yet." Medium. https://medium.com/data-science-in-your-pocket/gpt-5-openais-worst-release-yet-421558ad89f4 (9 agosto 2025)
[8] Reddit. "Chat GPT 5 was not for use, it was to get rid of free users all along." https://www.reddit.com/r/ChatGPT/comments/1mlkemm/chat_gpt_5_was_not_for_use_it_was_to_get_rid_of/ (9 agosto 2025)
[9] The Verge. "GPT-5 failed the hype test." https://www.theverge.com/openai/759755/gpt-5-failed-the-hype-test-sam-altman-openai
[10] Zurini, Andrea. "GPT-5 non è un upgrade. È un nuovo partner cognitivo." Digital Innovation Review. https://andreazurini.substack.com/p/gpt-5-non-e-un-upgrade-e-un-nuovo (8 agosto 2025)
[11] Hacker News. "GPT-5: Overdue, overhyped and underwhelming." https://news.ycombinator.com/item?id=44851557 (7 giorni fa)
[12] Windows Central. "GPT-5 promised a leap forward — Bill Gates thought otherwise." https://www.windowscentral.com/artificial-intelligence/openai-chatgpt/from-plateau-predictions-to-buggy-rollouts-bill-gates-gpt-5-skepticism-looks-strangely-accurate (1 giorno fa)
[13] Medium. "Bill Gates Was Right. And everyone should have listened." https://medium.com/utopian/bill-gates-was-right-0d972c59d39c (5 giorni fa)
[14] TechCrunch. "Current AI scaling laws are showing diminishing returns, forcing AI labs to change course." https://techcrunch.com/2024/11/20/ai-scaling-laws-are-showing-diminishing-returns-forcing-ai-labs-to-change-course/ (20 novembre 2024)
[15] The New Yorker. "What if A.I. Doesn't Get Much Better Than This?" https://www.newyorker.com/culture/open-questions/what-if-ai-doesnt-get-much-better-than-this (6 giorni fa)
[16] GovInfoSecurity. "The Scaling Strategy that's Failing AI Reasoning." https://www.govinfosecurity.com/scaling-strategy-thats-failing-ai-reasoning-a-29198 (6 giorni fa)
[17] GovInfoSecurity. "The Scaling Strategy that's Failing AI Reasoning." https://www.govinfosecurity.com/scaling-strategy-thats-failing-ai-reasoning-a-29198 (6 giorni fa)
[18] Medium. "The Hidden Cost of AI: How Machine Learning Is Draining Our Energy Resources." https://medium.com/@clairedigitalogy/the-hidden-cost-of-ai-how-machine-learning-is-draining-our-energy-resources-21d3d36af9d1 (4 aprile 2025)
[19] R&D World. "AI's great compression: 20 charts show vanishing gaps but still soaring costs." https://www.rdworldonline.com/ais-great-compression-20-charts-show-vanishing-gaps-but-still-soaring-costs/ (12 aprile 2025)
[20] The New Yorker. "What if A.I. Doesn't Get Much Better Than This?" https://www.newyorker.com/culture/open-questions/what-if-ai-doesnt-get-much-better-than-this (6 giorni fa)
[21] Pareto.AI. "Is Data Scarcity the Biggest Obstacle to AI's Future?" https://pareto.ai/blog/data-scarcity-in-llm-training (16 ottobre 2024)
[22] The Decoder. "OpenAI prepares to launch GPT-5, but big leaps are unlikely." https://the-decoder.com/openai-prepares-to-launch-gpt-5-but-big-leaps-are-unlikely/ (2 agosto 2025)
[23] Reddit. "GPT-5 arrives imminently. Here's what the hype won't tell you." https://www.reddit.com/r/artificial/comments/1mjd08m/gpt5_arrives_imminently_heres_what_the_hype_wont/ (6 agosto 2025)
[24] Stone, J. "Why bigger training sets must yield diminishing returns: An information-theoretic speed limit for AI." Neural Computation (2025)
[25] Thompson, N.C., et al. "Deep learning's diminishing returns: The cost of improvement is becoming unsustainable." IEEE Spectrum (2021)
[26] Bhardwaj, E., et al. "Limits to AI Growth: The Ecological and Social Consequences of Scaling." arXiv preprint arXiv:2501.17980 (2025)
[27] Cottier, B., et al. "The rising costs of training frontier AI models." arXiv preprint arXiv:2405.21015 (2024)
[28] Pragmatic Coders. "We analyzed 4 years of Gartner's AI hype so you don't make a bad decision." https://www.pragmaticcoders.com/blog/gartner-ai-hype-cycle (6 giorni fa)
[29] The Verge Sam Altman says ‘yes,’ AI is in a bubble https://www.theverge.com/ai-artificial-intelligence/759965/sam-altman-openai-ai-bubble-interview (15 Agosto 2025)
[30] Lu, C.P. "The race to efficiency: A new perspective on ai scaling laws." arXiv preprint arXiv:2501.02156 (2025)
[31] ScienceDirect. "Artificial intelligence as self-learning capital." https://www.sciencedirect.com/science/article/abs/pii/S0264999325002160 (6 agosto 2025)
[32] Atos. "Neuromorphic computing: The future of AI and beyond." https://atos.net/en/blog/neuromorphic-computing-the-future-of-ai-and-beyond (5 febbraio 2025)
[33] WeeTech Solution. "Top 15 Neuromorphic Computing Examples in 2025." https://www.weetechsolution.com/blog/neuromorphic-computing-examples (29 novembre 2024)
[34] Nature. "The road to commercial success for neuromorphic technologies." https://www.nature.com/articles/s41467-025-57352-1 (15 aprile 2025)
[35] Medium. "Understanding Scaling Laws in Embodied AI: Beyond Language Models." https://timothy-urista.medium.com/understanding-scaling-laws-in-embodied-ai-beyond-language-models-c1c34a30675f (11 novembre 2024)
[36] NVIDIA. "What is Embodied AI?" https://www.nvidia.com/en-us/glossary/embodied-ai/ (13 marzo 2025)
[37] AI2. "Embodied AI." https://allenai.org/embodied-ai (27 giugno 2025)
[38] SmythOS. "Symbolic AI and Neural Networks: Combining Logic and Learning." https://smythos.com/developers/agent-development/symbolic-ai-and-neural-networks/ (13 novembre 2024)
[39] UMNAI. "From Data to Logic: Inside Neuro-symbolic AI." https://www.umnai.com/framework/tech-blog/umnai-neuro-symbolic-ai (18 luglio 2025)
[40] SmythOS. "Symbolic AI and Neural Networks: Combining Logic and Learning." https://smythos.com/developers/agent-development/symbolic-ai-and-neural-networks/ (13 novembre 2024)
[41] TechXplore. "Scaling up neuromorphic computing for more efficient and effective AI." https://techxplore.com/news/2025-01-scaling-neuromorphic-efficient-effective-ai.html (24 gennaio 2025)
[42] Klein, Stephen. "Post-Linguistic Reasoning Substrate (PLRS)." LinkedIn. https://www.linkedin.com/posts/stephenbklein_this-is-a-dense-one-but-perhaps-density-activity-7363064641192685570-7x_w?utm_source=share&utm_medium=member_desktop&rcm=ACoAAArh54EBg3n6AMDTrFw9MXu1OBSpT_mL73o Founder & CEO di Curiouser.AI, Berkeley Instructor, Harvard MBA.
Chi sono e cosa faccio

Sono un consulente e formatore per l'innovazione digitale e l'AI.
Aiuto aziende e professionisti a navigare la trasformazione tecnologica con approccio strategico e pragmatico.
Con Digital Innovation Review ti porto conoscenze nuove e concrete: approfondimenti, casi reali, metriche, checklist — zero fuffa, solo ciò che ti fa muovere budget e persone.
Il prossimo passo lo scegli tu:
🆕 Nuovo qui? → Iscriviti alla newsletter: “Un approfondimento a settimana su AI e Digital Innovation”.🎙️Preferisci i Podcast alle Newsletter? Questa Newsletter ha anche un podcast: Kilobyte (disponibile su Substack, Youtube e Spotify) in cui partendo dalle notizie di attualità analizzo dei temi emergenti dell’Innovazione Digitale
🔗 Già lettore? → Seguimi su LinkedIn: “Un post al giorno per non restare indietro nella corsa all’Innovazione Digitale
⚡ Serve un boost immediato? → Prenota una consulenza qui: Scegli il formato di consulenza più adatto alla tua necessità
💎 Vuoi andare in profondità? → Digital Innovation Club: analisi tematiche, deep‑dive, toolkit operativi, briefing per manager & imprenditori.
🎓 Formazione seria? → Partirà a Settembre Beyond Academy: community gratuita + percorsi avanzati che combinano strategia e operatività.
🌐 Per tutto il resto c’è il mio sito: www.andreazurini.it


